INFORMAZIONI SU
INFORMAZIONI SU
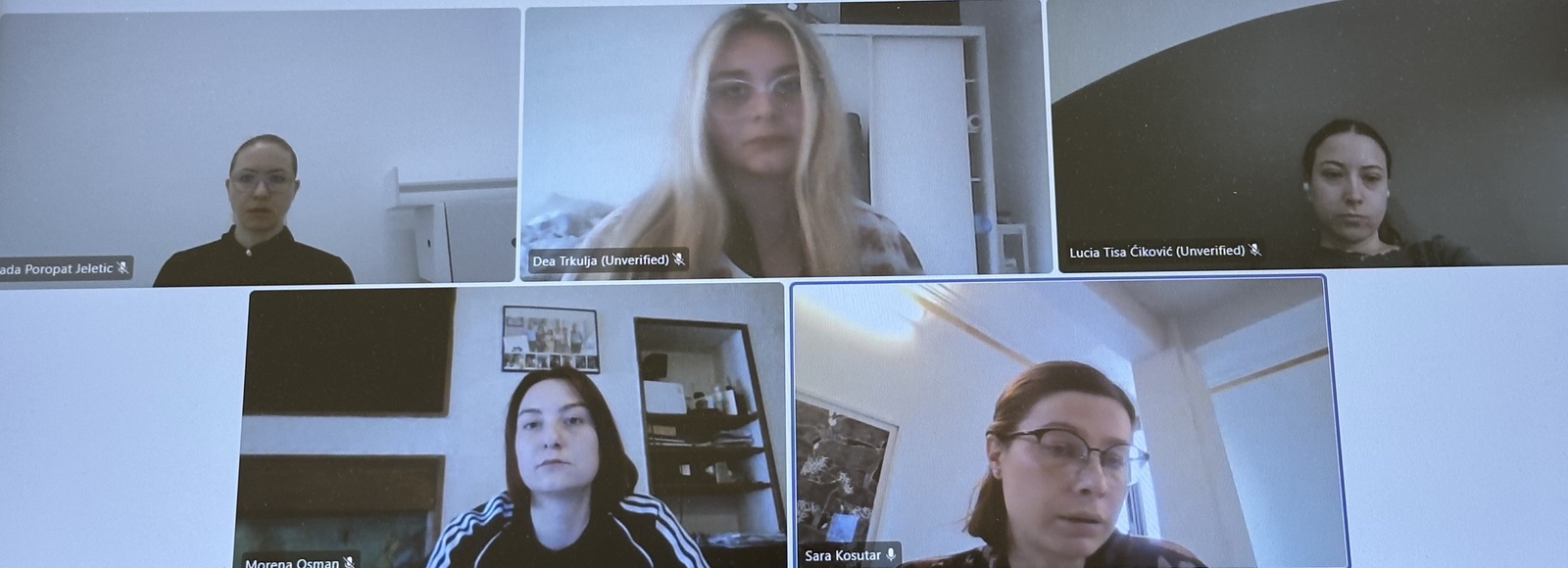
Lunedì 30 marzo 2026, nell’ambito delle attività del Centro di ricerca del patrimonio linguistico e culturale dell’Istria presso la Facoltà di Lettere e Filosofia dell’Università degli Studi “Juraj Dobrila” di Pola, la dott.ssa Sara Košutar (UiT – The Arctic University of Norway) ha tenuto un laboratorio specialistico online intitolato “Principi di codifica secondo il sistema CHAT nel programma CLAN”.
Il laboratorio era rivolto a ricercatori e studenti impegnati nella costruzione e nell’analisi di corpora di lingua parlata, con particolare riferimento ai partecipanti coinvolti nel progetto Neurocognitive Abilities and Early Bilingual Development: Language Exposure and Executive Functions – NeuroLEEF (Unione europea, NextGenerationEU). I partecipanti sono attivamente coinvolti nelle attività progettuali che comprendono la trascrizione e l’analisi di dati linguistici raccolti da bambini in contesti plurilingui. Le registrazioni audio utilizzate sono state raccolte presso la Scuola elementare “Edmondo De Amicis” di Buie nell’ambito del progetto scientifico internazionale Cross-linguistic Influence during Real-time Language Processing in Child Heritage Speakers – CLEAR, finanziato dalla Commissione europea per la ricerca e l’innovazione nell’ambito del programma Horizon Europe, Marie Skłodowska-Curie Actions (MSCA), sotto la direzione scientifica della dott.ssa Sara Košutar (UiT – The Arctic University of Norway), e realizzate dalla professoressa Arlene Kauzlarić Ocovich.
Dal punto di vista contenutistico, il laboratorio ha offerto una trattazione sistematica e metodologicamente rigorosa del sistema standardizzato di trascrizione CHAT (Codes for the Human Analysis of Transcripts) e della sua implementazione nell’ambiente CLAN (Computerized Language Analysis), uno strumento fondamentale per l’elaborazione e l’analisi dei corpora nell’ambito della piattaforma TalkBank. Particolare attenzione è stata dedicata alla strutturazione dei trascritti, alla segmentazione del discorso mediante unità comunicative (C-units), alla rappresentazione accurata degli elementi paralinguistici e dei fenomeni discorsivi, all’identificazione e codifica degli errori linguistici (fonologici, morfosintattici e lessicali), nonché alla marcatura delle variazioni sociolinguistiche e dei fenomeni di commutazione di codice (code-switching) nei contesti bilingui. Il valore principale del laboratorio risiede nella sua immediata applicabilità alla ricerca empirica, poiché le procedure illustrate si conformano a standard internazionalmente riconosciuti, garantendo così l’interoperabilità e la comparabilità dei dati all’interno delle risorse corpus-based globali. L’incontro si è svolto in un clima altamente interattivo, consentendo ai partecipanti di approfondire le competenze metodologiche necessarie per la ricerca contemporanea nei campi della psicolinguistica, del bilinguismo e dell’analisi del parlato.





Facoltà di Lettere e Filosofia
Via Aldo Negri 6, 1° piano
52 100 Pola
Croazia
T: +385 (52) 877 436, 099 5342 557
F: +385 211 713
E: ffpu-ured@unipu.hr
W: ffpu.unipu.hr
![]()
![]()
![]()
 Pristupačnost
Pristupačnost